Recommendation Systems : Part 1
My personal notes as I navigate understanding recommendation systems in depth
Preface : I am fairly new to NLP and recommendation systems. My goal is to understand recommendation systems in depth and in this process make my notes available here. I refer to courses, papers and video lectures that are referenced in the end.
Survey Paper : Deep Learning based Recommendation System : A survey and New Perspectives
Shuai Zhang, Lina Yao, Aixin Sun, Yi Tay
I picked this as my first material to read for a couple of reasons:
the paper is fairly recent, published in 2019 so it would cover most of the notable milestones in recommendation systems
just browsing through the pages showed me that though its a 28 page survey paper, the paper had a gradual progression through topics I am familiar with (CNN, Auto Encoders, MLP) to topics that I am yet to learn about
there are a number of topics discussed, hence the paper has good breadth and would serve as a good introduction to the topic without putting me into a rabbit hole for each topic
What are Recommendation Systems?
In one sentence, “Sell Products you could never sell before to users you could never sell to before”. In many sentences :
Identify things users like
Suggest new items, suggest items on topics you like
Provide a way to serve new content to users that they might have never thought of searching but are still relevant to them
Why use Recommendation Systems?
Recommendation systems were first developed based on a simple observation that individuals often rely on recommendations provided by others in making daily decisions.
Effective strategy to overcome information overload and consumer over-choice
Facilitates better user experience with personalization
Helps users discover items/movies/songs they have never thought of searching on their own
Provide users with content they did not know they wanted 😃
Keep users engaged with the product (YouTube, Netflix) —> deeper user satisfaction → deeper loyalty and trust
Allow the company to understand user trends and behavior —> reach the right users effectively
Terminology

Candidate Generation
Types:
Collaborative Filtering
If user A has agreed in the past with other users, the the other recommendations coming from these similar users should be relevant as well and of interest to user A.
Makes recommendations based on data from user’s historical interactions (ratings, feedback, browsing history). There is no meta data of the items, you learn item similarity and user similarity from the interactions of the user. Uses the “user-item interaction matrix” to figure this out. Generally have a way to figure out if the user liked an item. For example, comments, like and dislike button, times they watched a movie etc. Represent this in a matrix form like below :

In the above example, each row corresponds to a user and each column to a movie. Each element in the matrix shows rating information by a user (row) for a particular movie (column). In real-world examples such as Netflix or YouTube, you can see how this matrix would have millions of rows and columns. Due to the large number of items available in today’s information age, this matrix would also be very sparse.
Some of the elements in the matrix are also negative (-1). These are the cases where we have no rating available (the user has not watched that movie or has not rated it). You can generally use any value to represent such cases. Sparsity occurs when there are a large number of negative values than positive ones. Sparse matrices make it very tough to derive meaningful insights, and they take up more space in memory and increase computation complexity. There is also a very high chance that these matrices turn out to be skewed. Some users can be over-enthusiastic and rate everything, or some users may be binging through movies all day and rating them.
With the help of this matrix, we can now calculate the distance between items and users using distance metrics like Manhattan distance, Euclidean Distance, etc.
Implicit and Explicit Feedback:
Explicit feedback such as ratings, comments, and reviews gives us direct information if the user liked the item or not. However, not many users provide explicit feedback (I never do!).
In such situations, we need to look out for implicit feedback from users. This includes subtle clues like:
number of times users revisit a page
how long do they spend on the page
Search history
play counts
the number of clicks
and fraction of videos watched
Since implicit ratings are more readily available.
How can we embed users and items in the same embedding?
A simple one-dimensional embedding can be constructed like this, where we quantify how adult/childish the movie is.

Based on these values and along this axis, “Shrek” is a children's movie, and “Dark Knight Rises” has more adult themes. Based on this we can find out similar movies. We can then add additional dimensions. This will make embedding spaces larger and more sparse, but it would also provide us with a more accurate way to find similar items.

Adding the blockbuster and arthouse feature, we now have a 2D embedding space. We can now use dot products or any other metrics to find out how similar items are. We can now also integrate users into this embedding space. The coordinates of the users can be got by using implicit and explicit feedback from users.

Now since each user has a 2D coordinate and each item also has a 2D coordinate, we can find interaction values between each user and items and take the dot product of that. For user 1, the closest movies are “Shrek” and “Harry Potter”. Imagine this embedding space now with millions of users and items.
Hand-picking features may not be the best option. The better option is to allow models to learn features from data. Instead of deciding the factors we will assign values along (Children vs Adult, Blockbuster vs Arthouse), we can learn latent features from the user-item interaction matrix. This is done through factorization. The user-item interaction matrix can be factorized into item-factor embedding and user-factor embeddings.
Latent Vectors: Compressing data to find the best generalities to rely on. These are embeddings learned from data and not explicitly defined.

Using this concept, we can make predictions. For example, if we want to recommend a movie to user 4 we can find the dot product of user 4’s latent vector with every movie’s latent vector. The movie corresponding to the highest value of this dot product would be the best recommendation for the user 4. The dot product for user 4 and movie 3 is shown below.

Factorization Approaches
Because the user-interaction matrix gets very sparse (a large number of users and items). We can shrink down this matrix using matrix factorization. Break it down into two smaller matrices, the user matrix, and the item matrix.
Factor the user-interaction matrix into user factors and item-factors
If you have one factor, you can get the other by multiplying it
Given user ID, you can multiply by item factors to get predicted ratings for all items
You can use it to return top-rated items for this user
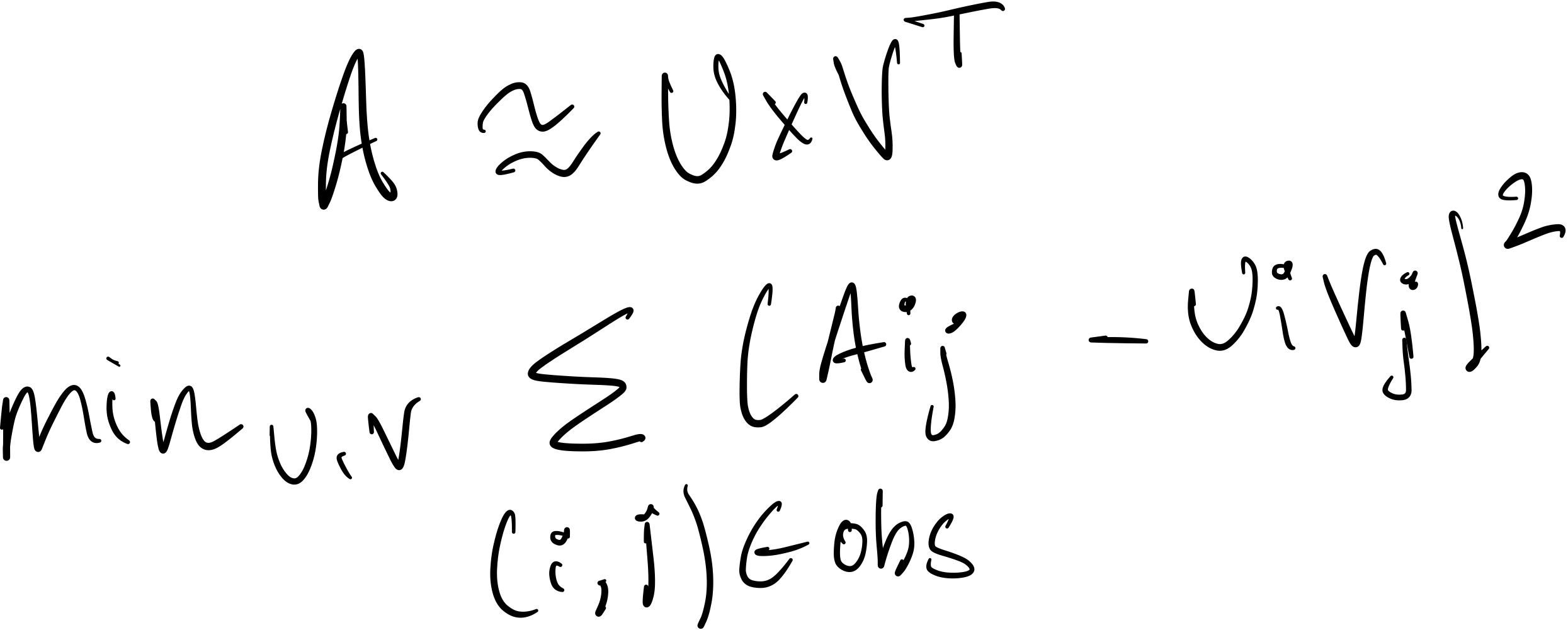
U and V are the two-factor matrices. The goal is to minimize the error between the original user interaction matrix A and the product UV. This resembles the least squared problem. Some of the ways to minimize this error are as follows :
Stochastic Gradient Descent (SGD)
Advantages: very flexible, parallel (easy to scale out)
Disadvantages: slow (many iterations to learn a good fit), hard to handle unobserved interaction pairs
Alternating Least Squares (ALS)
keeps U constant and solves for V and vice versa. Ignores missing values.
Advantages: parallel, faster convergence than SGD, easily handle unobserved data
Disadvantages: only works for least squares
Weighted Alternating Least Squares
Instead of completely ignoring the missing values, we give them a small weight. These small weights represent low confidence.

Pros of collaborative filtering :
no need to have metadata in the items
instead of requiring a lot of domain knowledge, collaborative filtering learns latent factors and can explore outside user’s personal bubble
no need to do market segmentation of the users
all you need is an User-Item interaction matrix.
feature representations can be learnt automatically without relying on engineering features / previously constructed features
collaborative filtering uses similarities between items and users simultaneously in an embedding space
Cons of collaborative filtering
cold Start for items occurs when there is not enough interactions - new users are added / new items are added. Because collaborative filtering depends on interactions between users and items, these situations give rise to bad recommendations. This is when content based systems should be used and a hybrid approach should be taken.
skewed and sparse matrices
lack of explicit user feedback forces to use implicit feedback which may need more complex approaches to understand user behavior
Content Based recommender Systems
Makes recommendations based on comparisons between items and users.
Use meta data of the items and users. If you like a comedy movie and u are from US, you may be recommended more comedy movies that are liked by people in the same area as you.
ex : If user A is similar to user B, and user B likes video 1, then the system can recommend video 1 to user A (even if user A hasn’t seen any videos similar to video 1).
How can you quantify that two items / users are similar?
Overlap in genres and themes of items
If two users have liked similar items in the past : the two users are similar
Compare properties of users and items in same embedding space (more rigorous method for ML)
Embedding : a map from our collection of items to some finite dimensional vector space. It provides a way of giving a finite vector value representation of users and items in our dataset.
Commonly used similarity measures
Dot Product
Cosine Similarity
Building a User Vector
A simple example of how you can build a user vector of a person who has rated movies from different genres.




The above user feature vector can now be used to predict movie ratings for movies that the user has not rated. These ratings can then be used to find the best recommendation movies for the user.


As shown above, use the user feature vector and multiply it with the movie feature vector. Then take a row wise summation to find the recommendation vector. We can see that “Shrek” seems to be the top recommendation for the user based on his previous ratings/likes/dislikes. This approach can be easily expanded to multi-user matrices.
Did you notice the feature vector in the example shows that the user dislikes “Action” genre the most. Is this accurate? Maybe not. If you notice, the user has not rated any action movie. This is one of the drawbacks of the content based filtering. It limits the recommendations to items similar to what the user has already seen and voted high. This limits exploration and expanding the interest of the user to new domains.
Pros of content-based filtering :
Does not need information about other users, easy to scale
can recommend niche items - does a good job finding rare items for the user
Cons of content-based filtering:
You need to construct features for the embedding space - tough for very complicated problems
Become very dependent on users’ interests and can not recommend things beyond that limited knowledge.
Need domain knowledge, and humans to annotate items and data
Knowledge Based Recommender Systems
These systems use explicit knowledge about users, items and recommendation criteria. Occurs mostly in situations where items are not purchased very often. Most often these systems ask users for their preferences before it starts making recommendations. Use this data to find similarities, etc age, and gender.
Pros:
No interaction data needed
Usually high fidelity data from user self-reporting - trust data more
Cons:
needs user data
need to be careful with privacy concerns
Keep the strengths of all three types of recommendation systems while getting rid of the disadvantages.
Hybrid Recommender Systems
Integrates all collaborative, content-based, and knowledge-based recommender systems. In a case where you have the interaction matrix and the metadata, you can use hybrid deep-learning approaches to combine content-based and collaborative methods. This takes in the advantages of all of them.
ex: YouTube uses a hybrid approach
Hybrid approaches can be used based on user activity. For example, if the user has a lot of reviews and likes, we can use content-based approaches. If not, we can use collaborative and knowledge-based. We can also use the outputs of all approaches and feed them into another complex model. This is known to be more accurate.
Why is Deep Learning popular in recommendation systems?
Deep Learning has the ability to effectively capture non-linear patterns and relationships in data. The advantage of deep learning models is that you can incorporate all kinds of queries into the input layer. This helps capture the essence of the users interests better and helps in the best recommendations. One example in which we can use deep learning may look like this :

The example deep learning model shown above can be used to predict user rating based on different attributes.
References :
https://www.sciencedirect.com/science/article/pii/S1110866515000341
Deep Learning based Recommendation System : A survey and New Perspectives : https://arxiv.org/abs/1707.07435